这些观察嵌入顺序输入到Transformer-XL中,其输出嵌入输入到MLP价值头、MLP策略头和Muesli LSTM模型步、

文章插图
不止few-shot
通过对Transformer-XL架构做了一个简单的修改,就可以在不增加计算成本的情况下增加有效的记忆长度 。
由于在视觉RL环境中的观察往往与时间高度相关,所以研究人员提出对序列进行子采样 。为了确保在子采样点之间的观察仍然可以被关注到,使用一个RNN对整个轨迹进行编码 , 可以总结每一步的最近历史 。
结果表明,额外的RNN编码并不影响模型中Transformer-XL变体的性能,但能够保持更远的记忆 。
5. 蒸馏
对于训练的前40亿步,研究人员使用一个额外的蒸馏损失用预训练教师模型的策略来指导AdA的学习,整个过程也称之为kickstarting
教师模型通过强化学习从头开始进行预训练,使用与AdA相同的训练程序和超参数,但教师模型没有初始蒸馏,并且具有较小的模型规模:教师模型只有2300万Transformer参数,而多智能体AdA拥有2.65亿参数 。
在蒸馏过程中,AdA根据自己的策略行动,教师模型根据AdA观察到的轨迹提供目标Logits;使用蒸馏可以摊销昂贵的初始训练期,并使智能体能够消除在训练的初始阶段学到的有害表征 。
然后将蒸馏损失与Muesli结合起来,最小化模型预测的所有行动概率与教师策略在相应时间段预测的行动概率之间的KL-散度 。
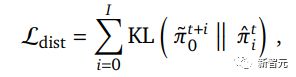
文章插图
研究人员还发现了一个有用的小操作 , 可以在蒸馏期间添加一个额外的L2正则化项 。
参考资料:
【强化学习也有基础模型了!DeepMind重磅发布AdA,堪比人类的新环境适应能力】https://arxiv.org/abs/2301.07608
相关经验推荐









- 怎样教孩子学习绘画 如何教孩子学习绘画
- 怎么能让孩子主动学习
- 一轮复习地理学习重点 有哪些重点地理知识点
- 《仙乐传说加强版》游戏强化功能和画面参数公布
- 松乳菇的种植技术在哪里可以学习
- 对话华创资本合伙人熊伟铭:冰封重启,2023年投资市场 “有风景也有迷雾”
- 孩子怎样才能学习好
- 学习书法的好处有哪些?,学书法的好处是什么?
- 怎么学习温室工程
- 古人也有食物造假吗,古代怎么监管食品安全